python中使用分步式进程计算
在python中使用多进程和多线程都能达到同时运行多个任务,和多进程和多线程的选择上,应该优先选择多进程的方式,因为多进程更加稳定,且对于进程的操作管理也更加方便,但有一点是多进程独有的杀手锏,多进程可以将进程分步到多台机器上跑,假如有很多个任务,一台机器即使开了多进程或者多进程跑起来还是要耗很多时间,那么这时就要想一下可否将任务分配到多台机器上跑,这样可以更快的完成任务。
在分步式进程运算中,进程之前的通信还是依赖于Queue,但此时的队列不能直接使用,需要使用multiprocessing.managers.BaseManager 进行包装,通过回调以后才能使用,既然是分步式的调用,那么应该有一个服务端和一个客户端,服务端通过网络协议将队列中的信息给各个客户端进行调用,客户端也可以通过队列将结果返回,然后服务端进行结果的收集展示,流程如下
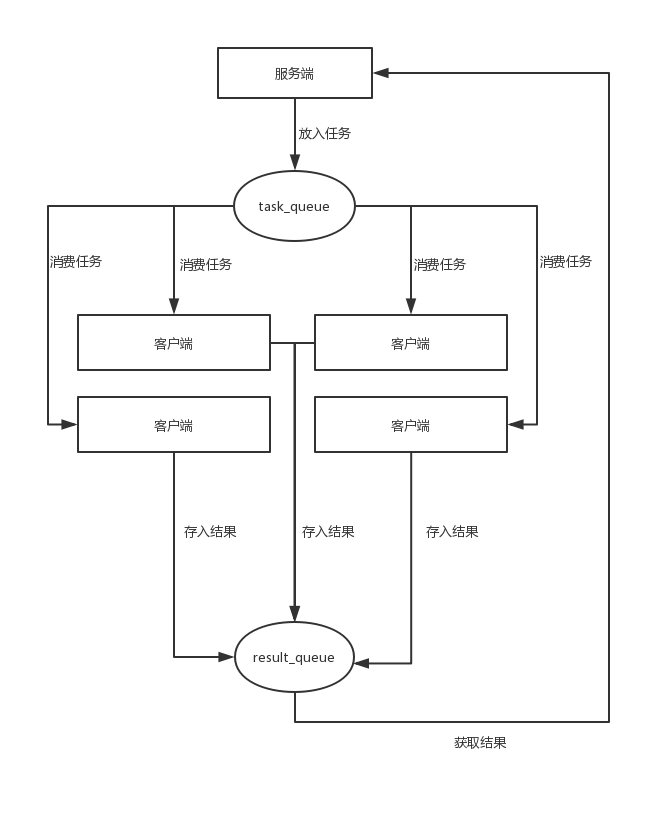
服务端将任务放到 task_queue 中,然后四个客户端通过网络端口从task_queue中获取到任务,然后进行计算,再将结果放到result_queue中,最后服务端统一处理结果。整体的流程比较清晰,只是需要强调,这里的队列不能是原始的队列,需要使用BaseManager 进行包装。
先看一下服务端的代码
#coding:gbk
import time, queue
from multiprocessing.managers import BaseManager
from multiprocessing import freeze_support
# 任务个数
task_number = 10
# 定义收发队列
task_queue = queue.Queue(task_number)
result_queue = queue.Queue(task_number)
def gettask():
return task_queue
def getresult():
return result_queue
def test():
# windows下绑定调用接口不能使用lambda,所以只能先定义函数再绑定
BaseManager.register('get_task', callable=gettask)
BaseManager.register('get_result', callable=getresult)
# 绑定端口并设置验证码,windows下需要填写ip地址,linux下不填默认为本地
manager = BaseManager(address=('127.0.0.1', 5002), authkey=b'123')
# 启动
manager.start()
try:
# 通过网络获取任务队列和结果队列
task = manager.get_task()
result = manager.get_result()
# 添加任务
for i in range(task_number):
print('Put task %d...' % i)
task.put(i)
# 每秒检测一次是否所有任务都被执行完
while not result.full():
print(task.qsize())
time.sleep(1)
for i in range(result.qsize()):
ans = result.get()
print('task %d is finish , runtime:%d s' % ans)
except:
print('Manager error')
finally:
manager.shutdown()
if __name__ == '__main__':
# windows下多进程可能会炸,添加这句可以缓解
freeze_support()
test()
这里重点说一下 BaseManager.register('get_task', callable=gettask) 这行代码,它的意思是注册一个get_task的操作,执行的操作是gettask()函数,上面定义了gettask()函数,返回的是task_queue,这也是之前说的不能直接使用queue.Queue,必须要使用通过BaseManager的register接口封装过的的队列,下面使用task = manager.get_task()来获取到这个队列。
manager = BaseManager(address=('127.0.0.1', 5002), authkey=b'123')
这行代码初始了一个manager,它绑定了本机的5002端口,并且在客户端连接的时候需要一个密码:123。
接下来看一下客户端代码。
#coding:gbk
import time, sys, queue, random
from multiprocessing.managers import BaseManager
BaseManager.register('get_task')
BaseManager.register('get_result')
conn = BaseManager(address = ('127.0.0.1',5002), authkey = b'123')
try:
conn.connect()
except:
print('连接失败')
sys.exit()
task = conn.get_task()
result = conn.get_result()
while not task.empty():
print(task.qsize())
n = task.get(timeout = 1)
print('run task %d' % n)
sleeptime = random.randint(0,3)
time.sleep(sleeptime)
rt = (n, sleeptime)
result.put(rt)
if __name__ == '__main__':
pass;
这里主要看以下的代码
BaseManager.register('get_task')
BaseManager.register('get_result')
这两个是注册函数,和之前的服务端所对应,之前服务端注册了这两个函数,这里才能注册使用,注意这里不能注册服务端没有注册的函数
运行一下,先运行服务端,然后再启两个cmd运行客户端,也可以在局域网中的另外的机器上运行,但是要修改服务端的ip地址
服务端的结果如下
Put task 0...
Put task 1...
Put task 2...
Put task 3...
Put task 4...
Put task 5...
Put task 6...
Put task 7...
Put task 8...
Put task 9...
task 0 is finish , runtime:3 s
task 1 is finish , runtime:0 s
task 2 is finish , runtime:2 s
task 4 is finish , runtime:1 s
task 3 is finish , runtime:3 s
task 6 is finish , runtime:1 s
task 7 is finish , runtime:0 s
task 5 is finish , runtime:3 s
task 8 is finish , runtime:2 s
task 9 is finish , runtime:3 s
两个客户端的结果分别如下 客户端1
10
run task 0
9
run task 1
8
run task 2
6
run task 4
5
run task 5
1
run task 9
客户端2
7
run task 3
4
run task 6
3
run task 7
2
run task 8
一起运行的截图如下
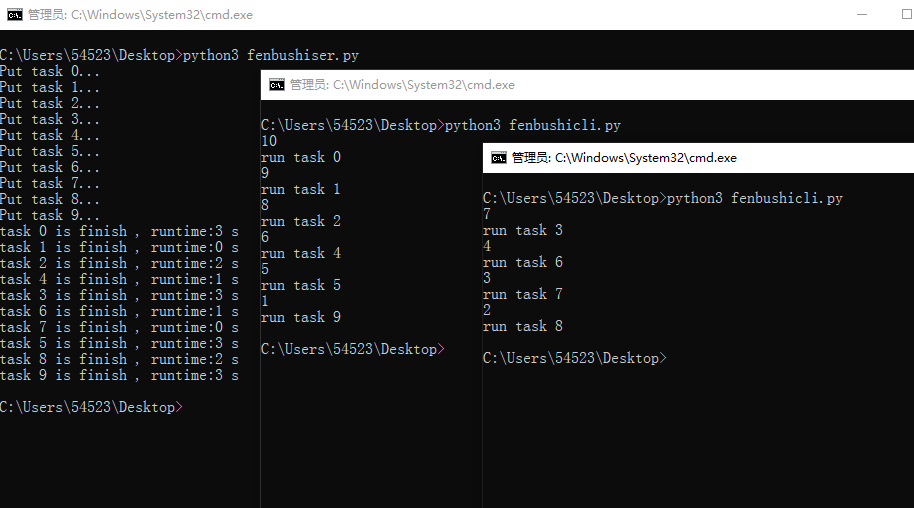
由于队列是线程安全的,所以这里不用加锁,在客户端中打印print(task.qsize()) 当前的队列大小,可以看到队列的信息中同步到各个客户端的。
最后还是要多说一句,分步式多进程虽然可以把任务分散到不同的机器上运行,可以处理多任务,但是如果此时服务端挂掉的话,任务就全丢掉了,所以在生产环境下还是考虑使用消息中间件如kafka等。
参考文章 python 分布式计算
