2.2 LangGraph 工具调用
大模型如果只依赖自身的知识,那么很难流行起来,也不会解决太多的问题,因为大模型自身的训练数据是有限的,像 agent 系统之所以能够流行,主要依赖大模型的决策能力,以前我们如果写程序,需要程序员按照产品经理的产品设计,设置好代码的运行逻辑依次的按照产品逻辑进行执行,比如用户询问北京的天气,那么会通过一定的代码比如关键词匹配,正则表达式或者NLP相关的工具来判断出用户的意图,还有分析出想要查询的地区是北京,然后调用相应的工具获取数据,过程中会有很大的出错概率,如参数分析的不准确,工具调用的不正确等,现在有了大模型,我们可以利用大模型的意图分析能力准确的得到需要调用哪个工具以及调用参数。
LangGraph 中可以利用LangChain 中的tool call 功能来实现工具的调用,本文先介绍一下在LangChain 中如何使用 tool call, 然后再使用LangGraph 工作流中调用工具。
一、LangChain 中的工具调用
langchain_community 中包含了很多实用的工具(大陆地区很多都是用不了的),以下使用 TavilySearchResults 作为演示。
| import os
from langchain_community.tools.tavily_search import TavilySearchResults
def _set_env(var: str, value):
if not os.environ.get(var):
os.environ[var] = value
_set_env("TAVILY_API_KEY", "tvly-xxxx")
tool = TavilySearchResults(max_results=2)
tools = [tool]
result = tool.invoke("Iphone 16 pro max 多少钱?")
print(result)
|
上面是工具自身的调用,并不需要大模型,就像是普通的 python 函数调用,只是这里的函数需要按照一定的规则进行定义。然后使用工具的invoke 方法来真正的调用工具。
二、自定义工具
由于langchain_community 中的工具很多我们是用不了的,所以这里我们来封装一个自定义工具,使用高德的天气查询接口来做一个天气查询的工具。高德的天气查询接口文档请查阅 https://lbs.amap.com/api/webservice/guide/api/weatherinfo
2.1 工具类的定义
参考 TavilySearchResults 工具的实现以及 LangChain 官方的 tools 文档 https://python.langchain.com/docs/how_to/custom_tools/ , 我这里使用继承自BaseTool 的方式来实现。
主要的流程包括
- 继承
langchain_core.tools.BaseTool 类
- 定义几个属性,
- name: 工具的名字。
- description: 工具的描述,这里的描述很重要,越详细越准确越好,后面的大模型是需要根据这里的描述来判断要调用哪个工具。
- args_schema: 参数的定义,
pydantic.BaseModel 类型,这里也需要对函数调用的参数进行详细的描述,越准确越好。
- 除了上面几个属性,如果工具还需要自己单独的属性,也需要在类里定义,如这个天气api 需要的api_key。
- 定义
_run 方法,实现真正的业务调用逻辑, 如果需要使用异步调用,则需要再定义 _arun 方法。
根据上面的规则,定义如下的查询天气 tool。
| import json
from typing import Type
import requests
from langchain_core.tools import BaseTool
from pydantic import BaseModel, Field
class GaoDeWeatherInput(BaseModel):
city: str = Field(description="要查询天气的城市名称")
class GaoDeWeather(BaseTool):
"""
高德天气查询
"""
name: str = "高德天气查询"
description: str = "高德天气查询,输入城市名,返回该城市的天气情况,例如:北京"
args_schema: Type[BaseModel] = GaoDeWeatherInput
api_key: str
def _run(self, city):
s = requests.session()
api_domain = 'https://restapi.amap.com/v3'
url = f"{api_domain}/config/district?keywords={city}"f"&subdistrict=0&extensions=base&key={self.api_key}"
headers = {"Content-Type": "application/json; charset=utf-8"}
city_response = s.request(method='GET', headers=headers, url=url)
City_data = city_response.json()
if city_response.status_code == 200 and City_data.get('info') == 'OK':
if len(City_data.get('districts')) > 0:
CityCode = City_data['districts'][0]['adcode']
weather_url = f"{api_domain}/weather/weatherInfo?city={CityCode}&extensions=all&key={self.api_key}"
weatherInfo_response = s.request(method='GET', url=weather_url)
weatherInfo_data = weatherInfo_response.json()
if weatherInfo_response.status_code == 200 and weatherInfo_data.get('info') == 'OK':
contents = []
if len(weatherInfo_data.get('forecasts')) > 0:
for item in weatherInfo_data['forecasts'][0]['casts']:
content = {}
content['date'] = item.get('date')
content['week'] = item.get('week')
content['dayweather'] = item.get('dayweather')
content['daytemp_float'] = item.get('daytemp_float')
content['daywind'] = item.get('daywind')
content['nightweather'] = item.get('nightweather')
content['nighttemp_float'] = item.get('nighttemp_float')
contents.append(content)
s.close()
return contents
else:
return "没有查询到该城市的天气信息"
weather_tool = GaoDeWeather(api_key='xxxx')
result = weather_tool.invoke("北京")
print(json.dumps(result, ensure_ascii=False, indent=4))
|
由于高德的天气接口需要传入城市的cityCode, 并不是城市名称,所以先要获取一下城市的citycode,再根据 citycode 获取气象数据。
调用上面自定义的天气查询接口得到如下输出
| [
{
"date": "2024-12-16",
"week": "1",
"dayweather": "晴",
"daytemp_float": "8.0",
"daywind": "北",
"nightweather": "晴",
"nighttemp_float": "-3.0"
},
{
"date": "2024-12-17",
"week": "2",
"dayweather": "晴",
"daytemp_float": "5.0",
"daywind": "北",
"nightweather": "晴",
"nighttemp_float": "-4.0"
},
...
]
|
上面的工具可以很好的运行,也成功获取到了天气数据,当我们在调用工具的时候,需要输入城市名的,但是用户在交互过程中,很难知道用户是怎么问的,如用户可能问
- 北京明天的天气如何?
- 上海后天会下雨吗?
- 我在浙江,晚上出门需要带雨伞吗?
当遇到这些问题时,传统的业务流程很难做到准确的分析调用,这时我们就需要使用大模型来分析规划调用哪个工具,以及调用工具时的参数。
接下来我们看一下如何使用大模型来调用。
三、大模型结合工具的使用
| weather_tool = GaoDeWeather(api_key='xxxx')
# 初始化大模型
llm = ChatOpenAI(
model_name="qwen-turbo",
temperature=0.7,
max_tokens=1024,
top_p=1,
openai_api_key="sk-xxxx",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
tools = [weather_tool]
# 定义一个工具名称和工具实例的字典,用于之后的工具调用
tools_by_name = {tool.name: tool for tool in tools}
# 将工具与大模型进行绑定
llm_with_tools = llm.bind_tools(tools)
# result 为第一次调用大模型的输出
result = llm_with_tools.invoke("北京明天的天气如何?")
outputs = []
if result.tool_calls:
for tool_call in result.tool_calls:
tool_name = tool_call.get("name")
if tool_name in tools_by_name:
tool = tools_by_name[tool_name]
tool_result = tool.invoke(tool_call.get("args"))
tool_message = ToolMessage(
content=json.dumps(tool_result, ensure_ascii=False),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
outputs.append(tool_message)
print(outputs)
|
上面的代码当第一次使用 result = llm_with_tools.invoke("北京明天的天气如何?") 调用大模型时,此时大模型如果判断出要使用某个工具时,那么会返回如下的数据
| {
"content": "",
...
"id": "run-5e1c35d1-bae8-4357-8841-b42487973d59-0",
"example": false,
"tool_calls": [
{
"name": "高德天气查询",
"args": {
"city": "北京"
},
"id": "call_0a9e00c8c4fd4686865bfe",
"type": "tool_call"
}
],
"invalid_tool_calls": [],
"usage_metadata": {
"input_tokens": 195,
"output_tokens": 20,
"total_tokens": 215,
"input_token_details": {},
"output_token_details": {}
}
}
|
注意到返回的数据中有个 tool_calls 字段,这是一个列表,因为有时候大模型可能分析出要调用多个工具,但是大多数情况下只有一个工具,并将调用这个工具的参数放到 args 里返回了。如上面的调用,告诉客户端,需要调用一个叫 高德天气查询 的工具,参数为 {"city": "北京"} , 当客户端拿到大模型的分析输出时,就会使用 tool.invoke(tool_call.get("args")) 来真正的进行工具调用。当得到工具的输出以后,将结果保存在 outputs 列表中,此时如果我们直接将工具的输出返回给用户,只是一堆json 数据,并没有真正回答用户的问题,所以这里还需要再次调用大模型,将用户的问题(北京明天的天气如何?)和工具的输出再次传给大模型,让大模型进行总结回答。
这里需要将之前的用户消息和ai返回的消息以及调用工具返回的消息放到一个列表里,最后再统一调用一次大模型。
| # 初始化一个用于存放消息的列表
messages = [HumanMessage(content="北京明天的天气如何?")]
result = llm_with_tools.invoke(messages)
messages.append(result)
outputs = []
if result.tool_calls:
for tool_call in result.tool_calls:
tool_name = tool_call.get("name")
if tool_name in tools_by_name:
tool = tools_by_name[tool_name]
tool_result = tool.invoke(tool_call.get("args"))
tool_message = ToolMessage(
content=json.dumps(tool_result, ensure_ascii=False),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
messages.append(tool_message)
outputs.append(tool_result)
final_result = llm_with_tools.invoke(messages)
print(final_result.content)
outputs.append(final_result)
|
- 初始化一个messages 来存放消息
result = llm_with_tools.invoke(messages) 为第一次调用大模型,用于让大模型分析要调用哪个工具以及调用工具时的参数。tool_result = tool.invoke(tool_call.get("args")) 为真正的调用工具,得到工具的输出。tool_message = ToolMessage(content=json.dumps(tool_result, ensure_ascii=False)) 为定义tool_message, 之后使用messages.append(tool_message)将工具的输出也放到消息列表里final_result = llm_with_tools.invoke(messages) 为最终调用大模型,根据用户的提问以及大模型的输出做最终的解答
得到的输出为
| 明天,也就是2024年12月17日,北京的天气预计是晴朗,白天的温度会达到5.0℃,风向为北风。夜间的温度将会下降到-4.0℃,依旧保持晴朗的天气。
...
|
此时就完成了整个工具的调用。
如果我问 “我在浙江,今天晚上出门需要带雨伞吗?”
得到的大模型输出为
根据浙江未来几天的天气预报来看,最近没有降雨的状况。未来几天的天气以晴天和多云为主,因此晚上出门暂时不需要准备雨伞。不过请注意保暖,因为夜间温度会降低至0到3度之间。如果有更长时间的天气计,请继续关注最新的天气信息。
四、LangGraph 调用工具
上面铺垫了这么多,终于进入了主题,如何在LangGraph 中调用工具? 我们来回顾总结一下上面langchain 进行工具调用的流程
- 定义工具,写清楚工具的描述和参数的描述信息
- 初始化大模型,并将工具绑定到大模型中
- 拿到用户的提问,进行第一次的大模型调用,得到大模型分析出来的需要调用哪个工具以及对应的参数
- 根据大模型返回的工具信息真正的执行工具调用
- 将之前的用户问题,AI的回答以及工具的输出再次发给大模型,得到最终的输出结果
这里有一些注意的地方,首先,大模型并不是每次都能返回工具调用的参数,如果用户的问题和工具一毛钱关系都没有,则大模型也是不会返回工具调用信息的,如用户问 "iphone 16 多少钱", 这个问题很明显和这个天气查询工具一点关系都没有,则大模型会直接回答问题。其次,大模型有时会返回多个工具调用,需要依次进行工具调用,虽然多数情况下只会返回一个工具调用。
清楚了LangChain 的工具调用,我们使用 LangGraph 来实现一下 。
- 初始化一个带有工具调用的大模型client
- 添加一个大模型调用节点(node),用于和大模型进行交互
- 当需要进行工具调用时,进行工具调用,此时需要一个条件路由函数
- 如果需要调用工具,则将工具调用的结果和之前的用户消息大模型消息再次请求一次大模型,得到的结果再次进行是否需要工具调用判断,也就是每次进行大模型调用都需要判断一下是否还需要工具调用
- 如果不需要进行工具调用,则直接将大模型生成的恢复返回给用户,结束工作流
- 整个graph 过程中的消息放到State 中进行节点之间的共享
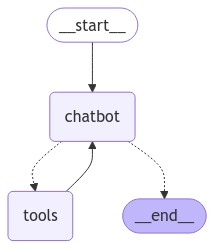
得到的流程如下
| import json
from typing import Type, TypedDict, Annotated
import requests
from langchain_core.messages import ToolMessage, HumanMessage, AIMessage
from langchain_core.tools import BaseTool
from langgraph.graph import add_messages, StateGraph, START, END
from pydantic import BaseModel, Field
from langchain_openai import ChatOpenAI
class State(TypedDict):
messages: Annotated[list, add_messages]
class GaoDeWeatherInput(BaseModel):
city: str = Field(description="要查询天气的城市名称")
class GaoDeWeather(BaseTool):
"""
高德天气查询,和上面的代码一样
"""
...
weather_tool = GaoDeWeather(api_key='xxxxxx')
llm = ChatOpenAI(
model_name="qwen-turbo",
temperature=0.7,
max_tokens=1024,
top_p=1,
openai_api_key="sk-xxxx",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
tools = [weather_tool]
llm_with_tools = llm.bind_tools(tools)
# 大模型执行节点
def chatbot(state: State):
return {"messages": [llm_with_tools.invoke(state["messages"])]}
# 工具执行节点
class BasicToolNode:
"""A node that runs the tools requested in the last AIMessage."""
def __init__(self, tools: list) -> None:
self.tools_by_name = {tool.name: tool for tool in tools}
def __call__(self, inputs: State):
messages = inputs.get("messages", [])
if messages:
message = messages[-1]
else:
raise ValueError("No message found in input")
outputs = []
for tool_call in message.tool_calls:
tool_result = self.tools_by_name[tool_call["name"]].invoke(
tool_call["args"]
)
outputs.append(
ToolMessage(
content=json.dumps(tool_result),
name=tool_call["name"],
tool_call_id=tool_call["id"],
)
)
return {"messages": outputs}
# 定义一个条件节点
def condition_tools(state: State):
ai_message = state["messages"][-1]
if ai_message.tool_calls:
return "tools"
return END
# 构建 graph
graph_builder = StateGraph(State)
# 添加节点
graph_builder.add_node("chatbot", chatbot)
graph_builder.add_node("tools", BasicToolNode(tools))
# 添加边
graph_builder.add_edge(START, "chatbot")
graph_builder.add_conditional_edges("chatbot", condition_tools)
graph_builder.add_edge("tools", "chatbot")
app = graph_builder.compile()
app.get_graph().draw_mermaid_png(output_file_path="graph_tool.png")
inputs = {"messages": [HumanMessage(content="北京后天的天气")]}
result = app.invoke(inputs)
print(result.get("messages")[-1].content)
|
参考这张图,chatbot 节点有两条虚线分别连接 tools 节点和 END 节点,虚线表示的是条件边,对应代码中的 add_conditional_edges,后面可能会走哪条分支,实线是确定的走向,对应代码为add_edge, 如 tools 节点之后确定要走chatbot 节点。
这里有一个很巧妙的设计,上面说过,工具调用结束以后,需要再次调用大模型对问题进行总结回答,这里的大模型调用没有在工具函数中定义,而是通过 LangGraph 的普通边来实现。
上面的代码定义了两个运行节点,一个是chatbot, 使用 chatbot 函数定义,另外一个是使用BasicToolNode 类定义的类节点,如果不明白可以查看前面的文章。
4.1 条件边
这里有个新的内容是,条件边,当某个节点的下一个节点可能走不同的分支时,需要使用条件边来连接可能运行的节点,添加条件边函数的第一个参数为起始节点,第二个参数为条件判断路由函数,这个函数需要返回一个字符串,就是下一个要走的节点,第三个参数为可选参数,paht_map, 为要走哪个节点的映射关系,一般不用写,只需要在条件判断函数中返回下一步要走哪个节点名称即可。
| def condition_tools(state: State):
ai_message = state["messages"][-1]
if ai_message.tool_calls:
return "tools"
return END
|
上面这个条件判断函数很简单,根据 state 中的最后一个message, 当调用完chatbot节点,如果大模型返回需要进行tool call, 则 message 中会存在 tool_calls 属性, 如果不需要进行tool call,则没有这个 tool_calls 属性,根据是否有tool_calls 属性来决定要走哪个节点,返回 tools 则执行工具调用,返回 END 则结束graph 执行。
和普通节点类似,条件节点也可以是类,需要定义 __call__ 方法,但是返回值也需要字符串。
五、问题拆解
5.1 多个工具
有时一个智能体可以调用多个工具,这种很常见,我们可以将多个工具绑定到大模型中,比如可以将上面的天气查询和实时搜索tavily一起绑定,这时大模型就有更多的能力了。
| tavily_tool = TavilySearchResults(max_results=2)
weather_tool = GaoDeWeather(api_key='xxxxxx')
# 将多个工具绑定到 llm 中
tools = [weather_tool, tavily_tool]
llm_with_tools = llm.bind_tools(tools)
inputs = {"messages": [HumanMessage(content="Tesla model Y 新版 有哪些特点?")]}
result = app.invoke(inputs)
|
这个问题显然与天气无关,大模型也不知道怎么回答,所以大模型返回需要调用tavily 工具,最终得到的内容为
| 新款特斯拉Model Y带来了许多显著的变化和升级,主要特点如下:
1. **外观设计**:新款Model Y采用了焕然一新的设计风格,前灯和尾灯组都进行了改进。车身侧面可能配备了黑色五辐轮毂,并且增加了运动感。
2. **新增七款车型**:除了原本的设计外,还将推出七款不同的车型版本,以适应更广泛的需求。
...
|
这时当用户询问天气相关的问题时,会调用 weather_tool, 当询问一些需要搜索才能知道的问题就会调用 tavily_tool。
总结
本文先介绍了在LangChain 中如何使用tool call 功能,以及如何自定义工具,然后在LangGraph 中如何通过图来进行工具的调用,最后又使用多个工具绑定到大模型,让大模型具备更多的能力。
下期预告
下一篇主要写一下如何流式输出工作流运行结果