2.1 LangGraph 初识
概述
当我们使用coze 搭建 AI 智脑体应用时,可以很方便的调用工作流,所谓的工作流,按照一定的规则,顺序的执行一系列的操作,其中,下游节点可能会用到上游节点的输出。
市场上已经有很多基于DAG(有向五环图)的流程执行系统,如dolphinscheduler,airflow, n8n等,但这些系统如果想要开发AI应用,还是需要很大的开发量,LangGraph 是 langchain 团队开发的用于大模型应用开发的框架,使用LangGraph ,我们可以很方便快捷地开发基于工作流的AI系统。
我最近在学习和使用LangGraph,我将记录一下我在使用过程中遇到的问题以及解决方案,以及我对智能体 agent 等的理解,大致可分为以下几类:
- LangGraph 工作流的构建与执行
- 使用 LangGraph 构建 Agent 系统
- FastAPI 整合LangGraph
- LangGraph 整合 Langfuse 进行日志追踪
未来也会不断地更新,可能也会不定期的穿插一些使用技巧等。
先从 LangGraph 的工作流构建与执行开始吧。
使用的版本:
python3.11, 这个是不是必须的,但是推荐使用3.11 及以上版本,因为后面流式输出会方便一些
LangGraph,0.2.58
一、简单的 chatbot
LangGraph 与 LangChain 深度结合,我们可以很方便的利用langchain 中的大模型接口进行开发,这次我使用千问大模型作为演示,当然国内很多大模型厂商的接口都是兼容openai 接口的。
| from typing import Annotated
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from langgraph.graph.message import add_messages
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(
model_name="qwen-turbo",
temperature=0.7,
max_tokens=1024,
top_p=1,
openai_api_key="sk-xxxxx",
openai_api_base="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
# 添加节点 node
graph_builder.add_node("chatbot", chatbot)
# 添加边 edgegraph_builder.add_edge(START, "chatbot")
graph_builder.add_edge("chatbot", END)
# 编译图
graph = graph_builder.compile()
# 生成一张png 图片
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
inputs = {
"messages": [
{"role": "user", "content": "你好,你是谁?"}
]
}
result = graph.invoke(inputs)
print(result)
|
以上代码构建了一个chatbot,回答用户的提问。代码的执行如下:
| {
'messages': [
HumanMessage(content='你好,你是谁?', additional_kwargs={}, response_metadata={}, id='2013904d-cf04-4f26-b7cf-073a670bde10'),
AIMessage(content='你好!我是Qwen,是阿里云开能够回答各种问题、提供信息和与用户进行自然语言对话的助手。有什么我可以帮你的吗?', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 43, 'prompletion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': 'qwen-turbo', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None}, id='run-4fb86565-7d0a-4acd-b9be-f570c7a3691c-0', usage_metadata={'input_tokens': 13, 'output_tokens': 43, 'total_tokens': 56, 'input_token_details': {}, 'output_token_details': {}})
]
}
|
可以通过 draw_mermaid_png 方法可以画一张图片,直观的展示这个简单的chatbot 的运行流程。
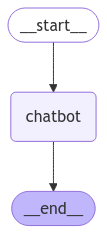
所谓千里之行始于足下,我们先从最简单的应用开始,开启我们的LangGraph 学习之旅。
二、问题拆解
2.1 什么是 TypedDict ?
上面的代码中,我们定义了State 类,这个类很重要,后面节点的执行,数据的流转都需要使用这个类,这个类继承自TypedDit类,这个又是什么呢? 和Dict 有什么区别呢?
首先,我们知道,在Python中,一个字典类型(Dict)的数据,值可以是任何类型,但是TypedDict 提供了一种约束,它约定了值的类型,这种约定可以方便之后的取值过程,同时IDE也会提供很好的代码提示, TypedDict 是 typing 模块中的一个工具,用于为字典提供静态类型检查支持。除此之外,它的用法和普通的 dict 是一样的。
如有如下代码
| from typing import TypedDict
class MyTypeDict(TypedDict):
name: str
age: int
xiaoming = MyTypeDict(name="小明", age=18)
xiaoming["school"] = "bj"
print(xiaoming.get("school"))
print(xiaoming.get("name"))
print(xiaoming.get("count"))
|
定义了一个MyTypeDict的类,这个类有name 和 age 两个属性,并没有school和 count 属性,在初始化对象时,传入name和age参数,之后就可以使用对象的get 方法获取,或者 xiaoming['name']
的方式获取。
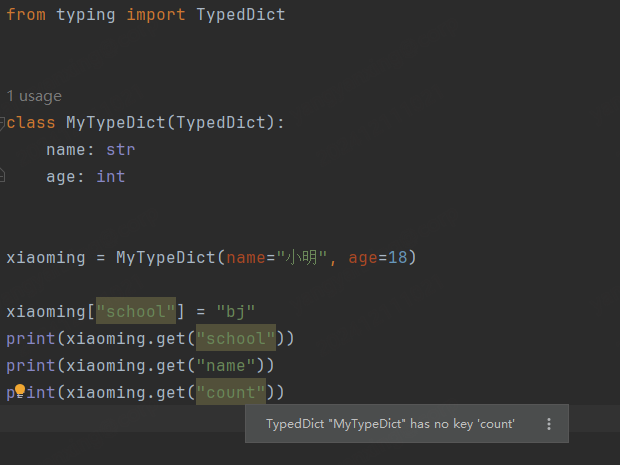
如上图展示,在pycharm 中, 当遇到没有在MyTypeDict 中定义的属性时,IDE会报一个警告,TypedDict "MyTypeDict" has no key 'count', 不过这并不会影响代码的运行,没有的属性会返回None,其行为和dict 是一样的。
2.2 如何理解 state?
state 为状态,我们可以理解为,在一个工作流的执行过程中,某一个节点需要上游节点的数据,这时就需要将节点的结果存储到某个数据结构中,这个state 就是做这个用的,当需要在节点间共享数据时,则会用到state, state 也会作为整个flow 运行结束时的返回值返回。
如上面的chatbot 代码
| class State(TypedDict):
messages: Annotated[list, add_messages]
graph_builder = StateGraph(State)
def chatbot(state: State):
return {"messages": [llm.invoke(state["messages"])]}
|
当 chatbot 节点执行结束以后,会返回一个字典,key 为 messages ,值为大模型的输出,这里langchain 已经转换为AIMessage对象, add_messages 为 LangGraph 内置的方法,通过该方法可以将大模型返回的AIMessage追加到 State 中的 messages 属性值中。
如果之后还有节点需要用到state 中的messages, 那么就可以通过 state['messages'] 获取到。我们来看一个简单的例子。
| from typing import TypedDict, Annotated
from langgraph.graph.message import add_messages
from datetime import datetime
from langgraph.graph import StateGraph, START, END
import time
import random
class State(TypedDict):
messages: Annotated[list, add_messages]
def test_node(state: State):
current_messages = state["messages"]
print(f"exec test node, messages: {current_messages}")
time.sleep(random.randint(1, 4))
current_time = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
return {"messages": [current_time]}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", test_node)
graph_builder.add_node("node2", test_node)
graph_builder.add_node("node3", test_node)
graph_builder.add_edge(START, "node1")
graph_builder.add_edge("node1", "node2")
graph_builder.add_edge("node2", "node3")
graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
result = graph.invoke(input={"messages": ["你好"]})
print(result)
|
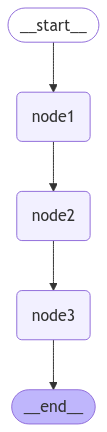
在 test_node 节点函数中,通过 current_messages = state["messages"] 获取到当前存储在state中的 messages, 之后再通过 {"messages": [current_time] 返回一个messages ,注意这里并不需要将新的消息追加到原有消息中,再返回,只需要返回新消息即可。新的消息会通过 add_messages 方法追加到 state 的 messages 里。
node1 节点打印
| exec test node, messages: [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}, id='dce982e4-0fbf-440a-a5c4-ac51119ae574')]
|
node2 节点打印
| exec test node, messages: [HumanMessage(content='你好', additional_kwargs={}, response_metadata={}, id='dce982e4-0fbf-440a-a5c4-ac51119ae574'),
HumanMessage(content='2024-12-11 11:17:16'additional_kwargs={}, response_metadata={}, id='74098941-1769-420a-b930-1e37ca4684c3')]
|
state 在LangGraph 非常重要,是工作流的基础,它贯穿于整个工作流中。
2.3 如何理解 state 中的 Annotated?
Annotated 是 typing 模块中引入的一种类型提示机制,它的主要目的是为类型提示附加注释信息,而不影响类型检查。例如,当一个类型有特定限制或条件时,你可以使用 Annotated 来描述这些附加信息。
在LangGraph 中的state 定义中,如果没有使用Annotated 定义,只是单纯的定义属性类型,那么默认节点返回属性值会将原有的数据覆盖。如下代码示例
| class State(TypedDict):
count: int
def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", test_node)
graph_builder.add_node("node2", test_node)
graph_builder.add_node("node3", test_node)
graph_builder.add_edge(START, "node1")
graph_builder.add_edge("node1", "node2")
graph_builder.add_edge("node2", "node3")
graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
result = graph.invoke(input={"count": 0})
print(result)
|
得到的运行结果为
| 当前state中的count值为:0, 即将更新为:3
当前state中的count值为:3, 即将更新为:6
当前state中的count值为:6, 即将更新为:6
{'count': 6}
|
state的定义为
| class State(TypedDict):
count: int
|
只是定义了count 的类型,并没有定义如何更新,则默认是覆盖原值。
在node1 执行时,当前值为0,更新为3,在node2 执行时,由于node1 将值更新为3, 所以打印为当前值为3,然后又将值更新为6。
2.4 state 是如何更新的?
上面介绍了 Annotated 在state中的作用,那么我们可以使用Annotated 来告诉LangGraph 如何更新state。
如下代码示例
| def update_count(current, new):
return current + new
class State(TypedDict):
count: Annotated[int, update_count]
def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count": count}
#... 和上面代码一样
result = graph.invoke(input={"count": 0})
print(result)
|
定义一个用于更新state中的count 的方法 update_count, 将每个节点的返回值进行相加操作。
这里的更新函数,要求有两个参数,当前值,和新值,在函数体里定义如何更新。如上面的update_count 方法,是将新值和原值进行相加操作。
运行得到的输出为
| 当前state中的count值为:0, 即将更新为:4
当前state中的count值为:4, 即将更新为:7
当前state中的count值为:11, 即将更新为:8
{'count': 19}
|
让我们来看一下代码是如何执行的。
- 首先,启动graph 时传入的初始值为
{"count": 0}
- 在node1 中,打印当前值为0,并且更新为 4,LangGraph 拿到node 的返回值
{"count": 4}, 将count 的值和最初的 {"count": 0} 通过 update_count 方法进行更新, 0+4 得到新值{"count": 4}
- 在node2 运行结束时,node2 返回的是
{"count": 7} , 通过 update_count 方法进行计算,4+7返回了 11
- 同理 node3 返回了8,通过
update_count 方法更新为11+8=19,最终工作流返回了 {'count': 19}
2.5 什么可以作为node?
LangGraph 中可以将任何函数作为节点node 函数,但是实际工作中,主要使用两类对象作为节点
- 函数 function
这里的函数定义为def test_node(state: State), 这个函数的第一个参数为工作流要使用的state 类,有时还会用到langchain 中的 RunnableConfig 类,来作为第二个参数,这个后面再做详细介绍。
如上面的代码示例
| class State(TypedDict):
count: Annotated[int, update_count]
def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count": count}
|
函数如果有返回值,则至少要返回一个state中定义的字段,如果 state 中有多个属性,不用全返回,只需要返回要更新的字段即可,LangGraph 会根据State 属性中Annotated定义的更新方法进行更新。
| class State(TypedDict):
count: Annotated[int, update_count]
messages: Annotated[list, add_messages]
def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count": count}
|
如上面的代码,State 中定义了 count 和 messages 两个属性,节点 test_node 只返回了 {"count": count}, 这样是可以的,但是如果“只”返回了一个在State 中没有定义的属性,是会抛异常的。
| def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count2": count}
|
上面的代码就会报错:langgraph.errors.InvalidUpdateError: Expected node count to update at least one of ['count', 'messages'], got {'count2': 6}
可以返回一个state中没有定义的属性,但是必须要同时至少返回一个state 定义的属性。
| def test_node(state: State):
count = random.randint(1,9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count": count, "count2": count+1}
|
count2 为state中没有定义的,这时是因为同时返回了 count, 所以这时候在返回count2是没有问题的。
结论: 当节点函数有返回值时,最少需要返回一个state 中定义的属性值。如果这个节点不需要更新state, 则可以不写返回值,节点函数用于执行某个操作即可,比如发个邮件,发个短信什么的。
- 类作为节点
上面使用函数作为节点使用起来相当简单,但是有一个问题,函数无法使用额外的参数,比如如下代码
| def test_node(state: State, name: str):
count = random.randint(1, 9)
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count2": count+1, "count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", test_node)
|
test_node 函数需要 name 参数,当使用上面的代码运行时,由于graph_builder.add_node("node1", test_node) 并没有传入name 参数,从而导致运行异常。
当然,也是有办法解决的,可以使用 functools.partial 包一层。
| from functools import partial
def test_node(state: State, name: str):
count = random.randint(1, 9)
print(f"当前输入的name值为:{name}")
print(f"当前state中的count值为:{state['count']}, 即将更新为:{count}")
return {"count2": count+1, "count": count}
graph_builder = StateGraph(State)
pnode = partial(test_node, name="test")
graph_builder.add_node("node1", pnode)
|
但这里推荐使用类来作为节点
| class TestNode:
def __init__(self, name):
self.name = name
def __call__(self, state: State):
count = random.randint(1, 9)
print(f"exec test class node, name: {self.name}, 返回count: {count} ")
return {"count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", TestNode("yang"))
graph_builder.add_node("node2", TestNode("yan"))
graph_builder.add_node("node3", TestNode("xing"))
graph_builder.add_edge(START, "node1")
graph_builder.add_edge("node1", "node2")
graph_builder.add_edge("node2", "node3")
graph_builder.add_edge("node3", END)
|
这里定义一个TestNode 类,将name作为属性传到TestNode类对象中,然后通过定义 __call__ 方法,来实现节点执行逻辑,__call__ 魔术方法为一个对象在被调用时执行的逻辑。
上面的代码执行结果为
| exec test class node, name: yang, 返回count: 6
exec test class node, name: yan, 返回count: 5
exec test class node, name: xing, 返回count: 3
{'count': 14, 'messages': []}
|
关于 __call__ 魔术方法,它是python 对象被调用时运行的函数
| class Test:
def __init__(self, name, age):
self.name = name
self.age = age
def __call__(self, *args, **kwargs):
print(f"name: {self.name}, age: {self.age}")
a = Test(name="zhangsan", age=18) # 生成Test 对象
b = Test(name="yangyanxing", age=28)
a() # 这里会调用 __call__ 魔术方法
b()
|
如果没有定义 __call__ 函数,则不能直接调用类对象。
三、深入理解
3.1 节点并行
上面展示的chatbot 以及节点函数的运行都是串行的,即上一个节点执行结束下一个节点才能开始运行,但是在很多 workflow 的执行过程中,如果两个节点并不会相互依赖对方数据,比如说一个节点在发邮件,一个节点是发短信,他们之间是可以并行执行的,这种节点在LangGraph 中应该如何定义呢?
| class EmailNode:
def __init__(self, email):
self.email = email
def __call__(self, state: State):
count = random.randint(1, 9)
date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"date: {date}, 将要执行发邮件操作,发给: {self.email}, 返回count: {count} ")
time.sleep(1)
return {"count": count}
class SMNode:
def __init__(self, phone):
self.phone = phone
def __call__(self, state: State):
count = random.randint(1, 9)
date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print(f"date: {date}, 将要执行发短信操作,发给: {self.phone}, 返回count: {count} ")
return {"count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", EmailNode("yang@qq.com"))
graph_builder.add_node("node2", SMNode("13811111111"))
graph_builder.add_node("node3", EmailNode("yangyanxing@test.com"))
graph_builder.add_edge(START, "node1")
graph_builder.add_edge(START, "node2")
graph_builder.add_edge(START, "node3")
# graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
result = graph.invoke(input={"count": 0})
print(f"date: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}, graph 执行结束")
print(result)
|
上面的代码会生成以下flow 流程图
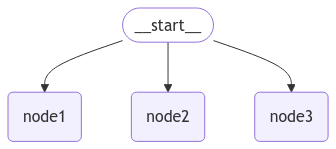
在LangGraph 中,添加并行节点非常简单,只需要调用 add_edge 方法,在起始节点使用相同的节点,如上面的代码,node1,node2,node3 有共同的父节点START,之后的节点就会并行执行。
注意上面的代码我并没有添加END节点,且在EmailNode 中使用 time.sleep(1) 休眠1秒钟。LangGraph 非常智能的等待所有的节点执行完毕。
| date: 2024-12-11 15:12:31, 将要执行发短信操作,发给: 13811111111, 返回count: 9
date: 2024-12-11 15:12:31, 将要执行发邮件操作,发给: yang@qq.com, 返回count: 9
date: 2024-12-11 15:12:31, 将要执行发邮件操作,发给: yangyanxing@test.com, 返回count: 3
date: 2024-12-11 15:12:32, graph 执行结束
{'count': 21, 'messages': []}
|
通过上面的结果打印,可以看到,三个节点是同时启动的,并且整个工作流执行时间是1秒钟。
3.2 并行节点的共同下游节点
我们想象一个场景,某个节点需要上游的两个节点执行结束以后再执行,而上游的两个节点是可以并行的,画出的流程图如下所示
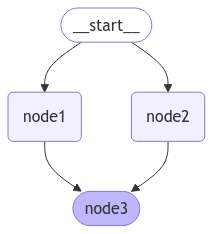
对于上面的工作流,我们需要依次的添加起始节点到终点的边,也可以一次性的使用list 添加。
| graph_builder = StateGraph(State)
graph_builder.add_node("node1", EmailNode("yang@qq.com", 1))
graph_builder.add_node("node2", EmailNode("yangyanxing@test.com", 2))
graph_builder.add_node("node3", SMNode("13811111111"))
graph_builder.add_edge(START, "node1")
graph_builder.add_edge(START, "node2")
# 此处,node1和node2 有共同的下游节点 node3
graph_builder.add_edge("node1", "node3")
graph_builder.add_edge("node2", "node3")
# 起始节点也可以使用list 的方式
# graph_builder.add_edge(["node1", "node2"], "node3")
graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
|
3.3 异步节点执行
当节点函数是个异步的函数,即使用async def 定义的函数,此时添加节点和添加边的方法不变,但是调用工作流的方法需要变为异步的ainvoke, 如下面代码所示。
| import asyncio
async def atest_node(state: State):
count = random.randint(1, 3)
print(f"当前state中的count值为:{state['count']},休眠秒数为:{count}, 即将更新为:{count}")
await asyncio.sleep(count)
return {"count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", atest_node)
graph_builder.add_node("node2", EmailNode("yangyanxing@test.com", 1))
graph_builder.add_node("node3", atest_node)
graph_builder.add_edge(START, "node1")
graph_builder.add_edge("node1", "node2")
graph_builder.add_edge("node2", "node3")
graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
graph.get_graph().draw_mermaid_png(output_file_path="graph.png")
result = asyncio.run(graph.ainvoke(input={"count": 0}))
# result = graph.invoke(input={"count": 0})
print(result)
|
有三个节点,node1 和node3 为异步函数 atest_node, node2 为 普通的 EmailNode 类,如果节点中包含有异步节点,那么就需要使用异步的启动函数,这里调用invoke的异步函数ainvoke,后面章节还可能调用异步的流式 (stream->astream)。
运行结果为
| 当前state中的count值为:0,休眠秒数为:3, 即将更新为:3
date: 2024-12-11 16:00:21, 将要执行发邮件操作,发给: yangyanxing@test.com, 返回count: 6
当前state中的count值为:9,休眠秒数为:3, 即将更新为:3
{'count': 12, 'messages': []}
|
类作为节点时也可以使用异步,在同步类调用时需要定义 __call__ 方法,如果需要异步调用,可以使用async def 定义 __call__ 魔术方法。
| class SMNode:
def __init__(self, phone):
self.phone = phone
async def __call__(self, state: State):
await asyncio.sleep(1)
count = random.randint(1, 9)
print(f"返回count: {count}")
return {"count": count}
|
3.4 节点如何传入更多的配置参数?
上面的章节,无论是函数作为节点或者类作为节点,在运行的时候,参数只有一个
| async def atest_node(state: State):
...
def test_node(state: State):
...
class EmailNode:
def __init__(self, email, sleep: int):
self.email = email
self.sleep = sleep
def __call__(self, state: State):
...
|
在LangGraph 运行工作流时,有时还需要传入更多的配置参数,这时我们可以通过 langchain_core.runnables.config.RunnableConfig (之后称为 RunableConfig)来实现,有了这个参数,我们可以传递更多的运行时配置,先来看一下这个RunnableConfig的定义
| class RunnableConfig(TypedDict, total=False):
"""Configuration for a Runnable."""
tags: list[str]
metadata: dict[str, Any]
callbacks: Callbacks
run_name: str
max_concurrency: Optional[int]
recursion_limit: int
configurable: dict[str, Any]
run_id: Optional[uuid.UUID]
|
节点运行的第一个参数是state 类型,除此之外还可以接收一个RunnableConfig 类型作为第二个参数。
RunnableConfig 也是一个TypedDict,它有一个 configurable 属性,这个属性接收一个字典,可以传入任何类型的值,这里我们可以使用configurable属性将运行时需要的配置信息传到节点中。
| async def atest_node(state: State, config: RunnableConfig):
...
async def atest_node(state: State, config: RunnableConfig):
...
class EmailNode:
def __init__(self, email, sleep: int):
self.email = email
self.sleep = sleep
def __call__(self, state: State, config: RunnableConfig):
...
|
| def test_node(state: State, config: RunnableConfig):
count = random.randint(1, 9)
configurable = config.get("configurable")
name = configurable.get("name")
print(f"当前state中的count值为:{state['count']},休眠秒数为:{count},name:{name}, 即将更新为:{count}")
return {"count2": count + 1, "count": count}
class EmailNode:
def __init__(self, email, sleep: int):
self.email = email
self.sleep = sleep
def __call__(self, state: State, config: RunnableConfig):
count = random.randint(1, 9)
date = datetime.now().strftime("%Y-%m-%d %H:%M:%S")
time.sleep(self.sleep)
configurable = config.get("configurable")
name = configurable.get("name")
print(f"date: {date}, 将要执行发邮件操作,发给: {self.email},name:{name}, 返回count: {count} ")
return {"count": count}
graph_builder = StateGraph(State)
graph_builder.add_node("node1", test_node)
graph_builder.add_node("node2", EmailNode("yangyanxing@tset.com", 1))
graph_builder.add_node("node3", test_node)
graph_builder.add_edge(START, "node1")
graph_builder.add_edge("node1", "node2")
graph_builder.add_edge("node2", "node3")
graph_builder.add_edge("node3", END)
graph = graph_builder.compile()
config = RunnableConfig(configurable={"name": "yyx"})
result = graph.invoke(input={"count": 0}, config=config)
print(result)
|
在代码中使用
| configurable = config.get("configurable")
name = configurable.get("name")
|
来获取配置信息,当启动工作流时,使用
| config = RunnableConfig(configurable={"name": "yyx"})
result = graph.invoke(input={"count": 0}, config=config)
|
来定义配置类,并且调用 invoke 方法时通过 config 参数传入,这样我们就可以在节点执行时拿到配置信息。
执行结果为
| 当前state中的count值为:0,休眠秒数为:1,name:yyx, 即将更新为:1
date: 2024-12-11 16:43:47, 将要执行发邮件操作,发给: yangyanxing@tset.com,name:yyx, 返回count: 5
当前state中的count值为:6,休眠秒数为:1,name:yyx, 即将更新为:1
{'count': 7, 'messages': []}
|
四、总结
本文通过非常简单的 chatbot 例子引出LangGraph 中几个非常关键的内容
- 节点(node), 什么是节点?哪些对象可以作为LangGraph 中的节点
- 状态(state), 状态作为LangGraph 中非常重要的概念,state 是节点间共享数据的基础,本文讲述了如何更新state,以及与state 相关的TypedDict 概念
- 如何并行的执行节点,在LangGraph 中非常方便地定义并行节点,只需要在同一个节点添加边即可
- 如何使用异步函数作为节点函数,异步函数与同步函数在添加节点和边时是以样的,工作流执行时需要使用异步的执行方法(ainvoke)来调用
- 通过使用 langchain 中的 RunnableConfig 类,在执行工作流时传入配置信息,这些配置信息在未来的日志追踪也需要使用。
下期预告
下一篇主要写一下如何流式输出工作流运行结果