golang中锁Mutex与通道channel的选择
Mutex和channel 都可以在并发环境下对资源进行保护,避免竞态, channel 在 golang 中一直被追捧,但是既然都能解决问题,但为什么还要弄两个东西呢?
查阅一些文章,发现有些时候对于channel过于追捧了。有时候该用Mutex 还是要用Mutex的,不要为了用channel 而用channle, 需要区分不同的场景
Mutex和channel 都可以在并发环境下对资源进行保护,避免竞态, channel 在 golang 中一直被追捧,但是既然都能解决问题,但为什么还要弄两个东西呢?
查阅一些文章,发现有些时候对于channel过于追捧了。有时候该用Mutex 还是要用Mutex的,不要为了用channel 而用channle, 需要区分不同的场景
golang 中的接口和别的面向对象中的接口有很大的不同。
接口的定义
定义一个Runable 接口,它有一个方法,run() , 这个方法没有参数也没有返回值
结构体可以定义一个方法,如果某个结构体定义了run() 方法,则说明该结构体实现了 Runable 接口,并不像java 或者 python 中的类,在定义的时候在显示的说明继承自哪个接口。
golang 中结构体可以看成面向对象编程中的类,可以为结构体定义方法,注意这里的方法和函数的区别,函数的定义是没有接收者的,方法是有接收者(receiver)的,这里的接收者可以是实例指针形式或者实例形式,鉴于性能的原因,recv 最常见的是一个指向 receiver_type 的指针,(因为我们不想要一个实例的拷贝,如果按值调用的话就会是这样),特别是在 receiver 类型是结构体时,就更是如此了。
golang 中的切片(slice) 和 python 中的 list 很像,但是又有很多不一样的地方,本文总结一下,当某个函数的参数是切片类型的时候的一些特性。
近期的自动化测试项目中有个关于测试内部IM通信软件的需求,在了解到各个客户端的相应技术栈实现以后,在mac中的应用使用的是electron 技术,我们也对相应的技术进行调研,此文记录一下在关于electron应用的自动化测试。
在我们测试平台中,有很多测试手机,对于某些手机,我们预计它只能跑特定的任务,或者某个手机会有一些特定的状态,如充电中,人工操作,手机清理中,当手机处于不同的状态会有一些不同的处理动作,此时我们会有哪些解决方案呢?
首先想到的应该是打标签,在数据库中新创建一个字段,比如叫tag,修改某个手机的状态,就修改一下这个tag字段。
但是这里有一个问题,如果某个手机拥有两个或者更多的标签,比如该手机正在充电,并且人工操作,那个我这个标签应该设置为多少? 如果在mysql中可以将该字段设置为charging,oping, 但是我们进行搜索的时候就有些麻烦了,比如我要过滤出正在充电的手机,sql 语句大概是这样的
终于忍受不了hexo了,换了个电脑,原来的东西基本上都迁移不过来,node版本,各种插件的依赖,不同的版本又会不一样,遇到各种编译错误,编译慢。。。。
受不了了,终于决定将博客从hexo迁移到hugo了,一开始还有点犹豫不舍得,转过来之后,真香!
最近尝试使用 beego 来初始化一个项目,按照文档来一步步的操作。 由于初次尝试使用golang来构建 这里也记录一下自己在初始化的时候所遇到的问题与解决。 由于也是新手,所以遇到的问题可能比较低级,但是这也作为以后熟练使用框架的一些基础吧
最近在做的项目中,需要将手机中的视频流或者音频流发送给服务端,再由服务端转发给浏览器端,起初我使用redis作为中转,将数据发到redis中,再由redis的发布订阅功能,整体架构如下
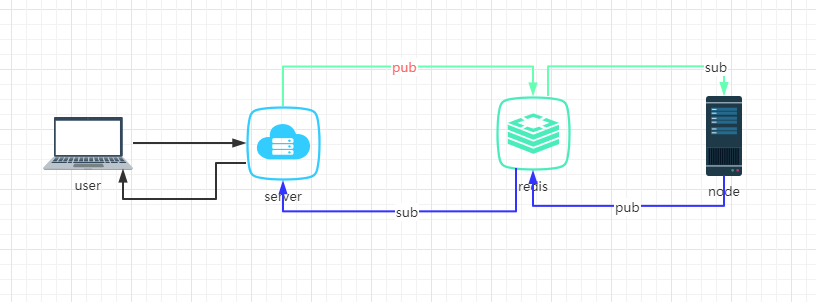
主要是利用了redis的pub/sub功能,这种方案也没有什么问题,但是整体的性能瓶颈受redis的影响。
最近接触到socketio,发现这种需求可以使用它来实现,但是网上查找了一些资料,在python的使用中,主要还是flask-socketio与原生的应用上,由于目前项目使用Tornado来构建,所以用了几天时间将socketio与Tornado的融合使用。
本教程会分几篇来介绍,主要以下几个章节
之前一直使用tornado做项目,数据库一直使用mongo与redis居多,凭借其优异的异步特性工作的也很稳定高效,最近的项目需要使用 mysql ,由于之前在使用mongo与redis时所使用的moto与aioredis来异步的执行数据库操作,所以在网上查询了异步操作mysql的库, 本文记录一下异步操作中所遇到的问题与相应的解决方案。