python中Mixin混入类的用法
Mixin 在 python 中也不是什么新鲜的东西,只是一种编程思想的体现,利用其可以多继承的语言特点,从而达到一种灵活的编程方式。
最近在看sanic的源码,发现有很多Mixin的类,大概长成这个样子
Mixin 在 python 中也不是什么新鲜的东西,只是一种编程思想的体现,利用其可以多继承的语言特点,从而达到一种灵活的编程方式。
最近在看sanic的源码,发现有很多Mixin的类,大概长成这个样子
最近想要看下go与python的性能到底有多少差异,不比不知道,差距还是蛮大的,为了方便实验,两个后台服务都访问相同的redis服务器, 简单的使用get 命令,获取一个值, 再通过json 格式返回
最近在对系统中某个接口进行压力测试的时候发现,有个redis的查询接口大量的报错,于是查看后台日志,发现是aioredis 报了Too many connections, 起初我认为是由于在进行压力测试,由于这个接口需要访问redis数据,同一时间来了大量的请求,所以会对redis服务器造成大量的请求,redis服务器抗不住返回了Too many connections 错误,但是经过排查不是这样的。
最近使用号称 python web 框架中性能最为强悍的框架 sanic , 搭建了项目的基础环境与项目框架,但是在是否使用ORM 的时候犯了选择困难综合症了,对于一个追求性能的框架,在使用了 ORM 以后必定会对性能有些影响,但是影响究竟有多大呢? ORM 的存在也是有它的理由的, 那么它的优点能否消除它在性能上的损耗呢?
近期的自动化测试项目中有个关于测试内部IM通信软件的需求,在了解到各个客户端的相应技术栈实现以后,在mac中的应用使用的是electron 技术,我们也对相应的技术进行调研,此文记录一下在关于electron应用的自动化测试。
最近在做的项目中,需要将手机中的视频流或者音频流发送给服务端,再由服务端转发给浏览器端,起初我使用redis作为中转,将数据发到redis中,再由redis的发布订阅功能,整体架构如下
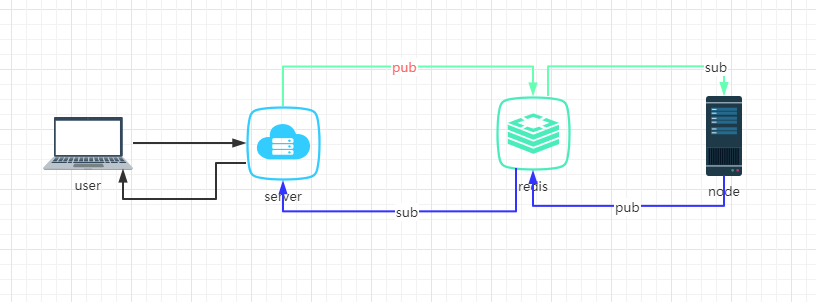
主要是利用了redis的pub/sub功能,这种方案也没有什么问题,但是整体的性能瓶颈受redis的影响。
最近接触到socketio,发现这种需求可以使用它来实现,但是网上查找了一些资料,在python的使用中,主要还是flask-socketio与原生的应用上,由于目前项目使用Tornado来构建,所以用了几天时间将socketio与Tornado的融合使用。
本教程会分几篇来介绍,主要以下几个章节
之前一直使用tornado做项目,数据库一直使用mongo与redis居多,凭借其优异的异步特性工作的也很稳定高效,最近的项目需要使用 mysql ,由于之前在使用mongo与redis时所使用的moto与aioredis来异步的执行数据库操作,所以在网上查询了异步操作mysql的库, 本文记录一下异步操作中所遇到的问题与相应的解决方案。
在python中使用日志最常用的方式就是在控制台和文件中输出日志了,logging模块也很好的提供的相应的类,使用起来也非常方便,但是有时我们可能会有一些需求,如还需要将日志发送到远端,或者直接写入数据库,这种需求该如何实现呢?
经常会看到有些代码中使用 functools.partial 来包装一个函数,之前没有太了解它的用法,只是按照别人的代码来写,今天仔细看了一下它的用法,基本的用法还是很简单的。
最近在使用flask的时候,有一个比较麻烦的事情,在跳转网页的时候需要设置cookie,使用单独设置cookie与单独跳转都比较简单,
可以看到,设置cookie的response 最后是通过return 回来的,但是上面的网页跳转则是通过redirect() 函数返回的,所以这两个没法同时的使用。
查看redirect() 的源码
可以看到,其实redirect函数也是通过构造一个response最后再将这个resonse return 出去,所以我们是否可以构造一个类似于redirect函数中的response对象,然后设置好status code是不是就可以了呢?
运行上面的代码,发现停留在/test 页面,显示上面的make_response的文字,并没有跳转,但是cookie中已经有display的cookie了,说明设置cookie成功了,跳转也成功了一半,只是它没有真正的跳转,还需要在网页上点击一下。
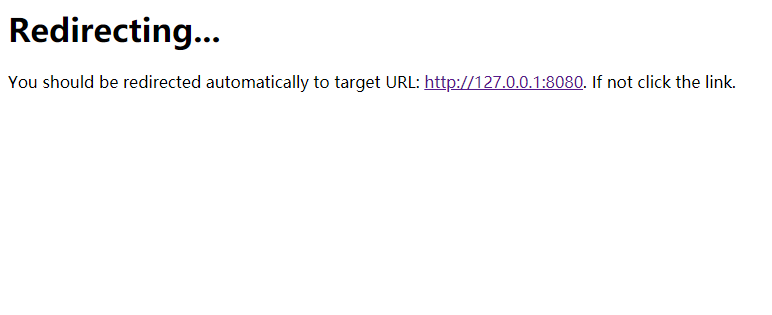
redirect函数中是通过 response.headers["Location"] = location 来设置的,在make_response 的返回响应对象中是通过response.location = 'xxxx' 来设置的
这时就可以正常的跳转了