使用python抓取360搜索联想词
几乎所有的搜索引擎都提供联想词提示,这个小脚本其实功能性不大,只当作使用urllib2发http请求和如何使用代理来访问
参考文章
http://video.sina.com.cn/v/b/113293169-1631501663.html
http://obmem.info/?p=47
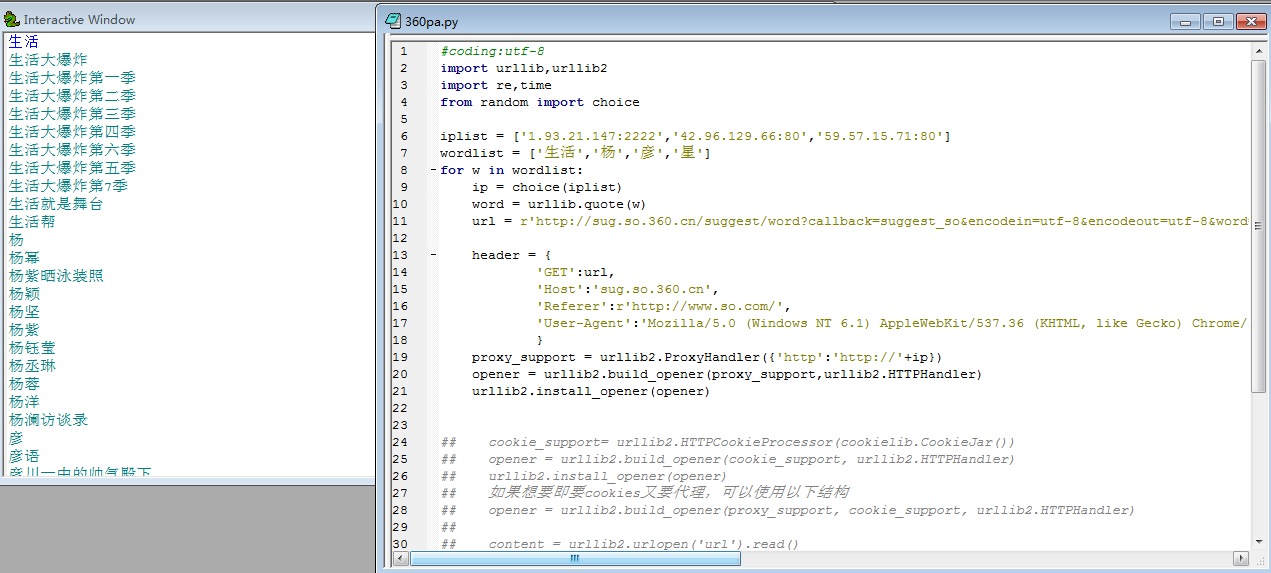
| #coding:utf-8
import urllib,urllib2,cookielib
import re,time
from random import choice
iplist = ['1.93.21.147:2222','42.96.129.66:80','59.57.15.71:80']#代理的列表,可以到网上搜,有好多
wordlist = ['生活','杨','彦','星']#想要搜索的关键词列表
for w in wordlist:
ip = choice(iplist)
word = urllib.quote(w)#使用urllib库中的quite方法将关键词进行编码
url = r'http://sug.so.360.cn/suggest/word?callback=suggest_so&encodein=utf-8&encodeout=utf-8&word=%s'% word
#用一个字典来存储header里的内容,这样做主要是为了不让360搜索来屏蔽机器人的采集
#可以使用firebug等工具来查看
header = {
'GET':url,
'Host':'sug.so.360.cn',
'Referer':r'http://www.so.com/',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'
}
#以下是采用代理方式来访问360搜索
proxy_support = urllib2.ProxyHandler({'http':'http://'+ip})
opener = urllib2.build_opener(proxy_support,urllib2.HTTPHandler)
urllib2.install_opener(opener)
## cookie_support= urllib2.HTTPCookieProcessor(cookielib.CookieJar())
## opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
## urllib2.install_opener(opener)
## 如果想要即要cookies又要代理,可以使用以下结构
## opener = urllib2.build_opener(proxy_support, cookie_support, urllib2.HTTPHandler)
##
## content = urllib2.urlopen('url').read()
req = urllib2.Request(url) #创建一个请求
#把header元素加入到请求中
for key in header:
req.add_header(key,header[key])
html = urllib2.urlopen(req).read()
ss = re.findall(""(.*?)"",html) #使用正则将联想词匹配出来
for item in ss:
print item
time.sleep(3)
|