使用web.py在BAE建立自已的电影网站
最近在网上看了一篇文章使用web.py在BAE上建立电影网站,http://www.51bigfool.com/%E6%88%91%E6%98%AF%E5%A6%82%E4%BD%95%E7%94%A8bae%E5%92%8Cweb-py%E6%89%93%E9%80%A0%E8%B1%86%E7%93%A3%E7%94%B5%E5%BD%B1top100%E7%9A%84.html 我自已也在此基础上做了一些改进,也在一点点的熟悉使用web.py这个框架,可以看一下我弄了一半的应用 http://movie.yangyanxing.com
准备 BAE web.py
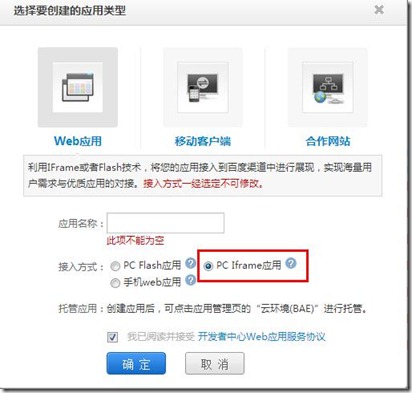
在BAE上建立一个python的应用
快速创建即可,选择Iframe