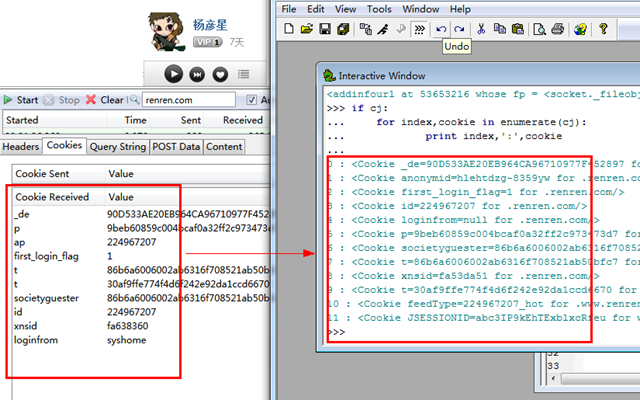
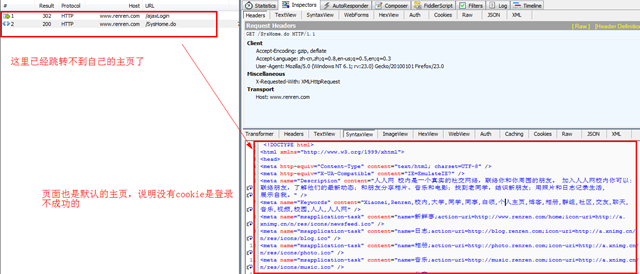
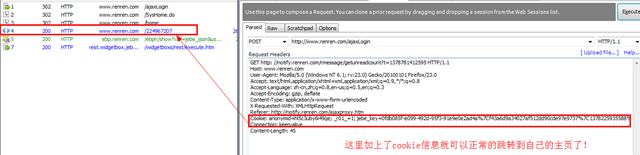
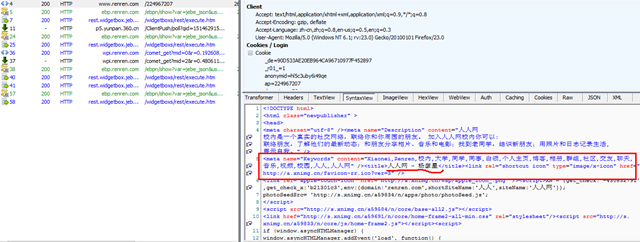
>>>importurllib>>>importurllib2,cookielib>>>login_page="http://www.renren.com/ajaxLogin">>>cj=cookielib.CookieJar()>>>opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))>>>opener.add_handler=[('User-agent','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)')]>>>data=urllib.urlencode({"email":'username',"password":'password'})>>>opener.open(login_page,data)<addinfourlat53653216whosefp=<socket._fileobjectobjectat0x03307B70>>>>>ifcj:...forindex,cookieinenumerate(cj):...printindex,':',cookie...0:<Cookie_de=90D533AE20EB964CA96710977F452897for.renren.com/>1:<Cookieanonymid=hlehtdzg-8359ywfor.renren.com/>2:<Cookiefirst_login_flag=1for.renren.com/>3:<Cookieid=224967207for.renren.com/>4:<Cookieloginfrom=nullfor.renren.com/>5:<Cookiep=9beb60859c004bcaf0a32ff2c973473d7for.renren.com/>6:<Cookiesocietyguester=86b6a6006002ab6316f708521ab50bfc7for.renren.com/>7:<Cookiet=86b6a6006002ab6316f708521ab50bfc7for.renren.com/>8:<Cookiexnsid=fa53da51for.renren.com/>9:<Cookiet=30af9ffe774f4d6f242e92da1ccd6670for.renren.com/xtalk/>10:<CookiefeedType=224967207_hotfor.www.renren.com/>11:<CookieJSESSIONID=abc3IP9kEhTExblxcRfeuforwww.renren.com/>>>>
#encoding=utf-8importurllib2importurllibimportcookielibdefrenrenBrower(url,user,password):login_page="http://www.renren.com/ajaxLogin"try:cj=cookielib.CookieJar()opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))opener.addheaders=[('User-agent','Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)')]data=urllib.urlencode({"email":'user',"password":'password'})opener.open(login_page,data)op=opener.open(url)data=op.read()returndataexceptException,e:printstr(e)printrenrenBrower("http://www.renren.com/home","用户名","密码")
fromsgmllibimportSGMLParserimportsys,urllib2,urllib,cookielibclassspider(SGMLParser):def__init__(self,email,password):SGMLParser.__init__(self)self.h3=Falseself.h3_is_ready=Falseself.div=Falseself.h3_and_div=Falseself.a=Falseself.depth=0self.names=""self.dic={}self.email=emailself.password=passwordself.domain='renren.com'try:cookie=cookielib.CookieJar()cookieProc=urllib2.HTTPCookieProcessor(cookie)except:raiseelse:opener=urllib2.build_opener(cookieProc)urllib2.install_opener(opener)deflogin(self):url='http://www.renren.com/PLogin.do'postdata={'email':self.email,'password':self.password,'domain':self.domain}req=urllib2.Request(url,urllib.urlencode(postdata))self.file=urllib2.urlopen(req).read()#print self.filedefstart_h3(self,attrs):self.h3=Truedefend_h3(self):self.h3=Falseself.h3_is_ready=Truedefstart_a(self,attrs):ifself.h3orself.div:self.a=Truedefend_a(self):self.a=Falsedefstart_div(self,attrs):ifself.h3_is_ready==False:returnifself.div==True:self.depth+=1fork,vinattrs:ifk=='class'andv=='content':self.div=True;self.h3_and_div=True#h3 and div is connecteddefend_div(self):ifself.depth==0:self.div=Falseself.h3_and_div=Falseself.h3_is_ready=Falseself.names=""ifself.div==True:self.depth-=1defhandle_data(self,text):#record the nameifself.h3andself.a:self.names+=text#record saysifself.h3and(self.a==False):ifnottext:passelse:self.dic.setdefault(self.names,[]).append(text)returnifself.h3_and_div:self.dic.setdefault(self.names,[]).append(text)defshow(self):type=sys.getfilesystemencoding()forkeyinself.dic:print((''.join(key)).replace(' ','')).decode('utf-8').encode(type),((''.join(self.dic[key])).replace(' ','')).decode('utf-8').encode(type)if__name__=='__main__':renrenspider=spider('email','password')renrenspider.login()renrenspider.feed(renrenspider.file)renrenspider.show()